
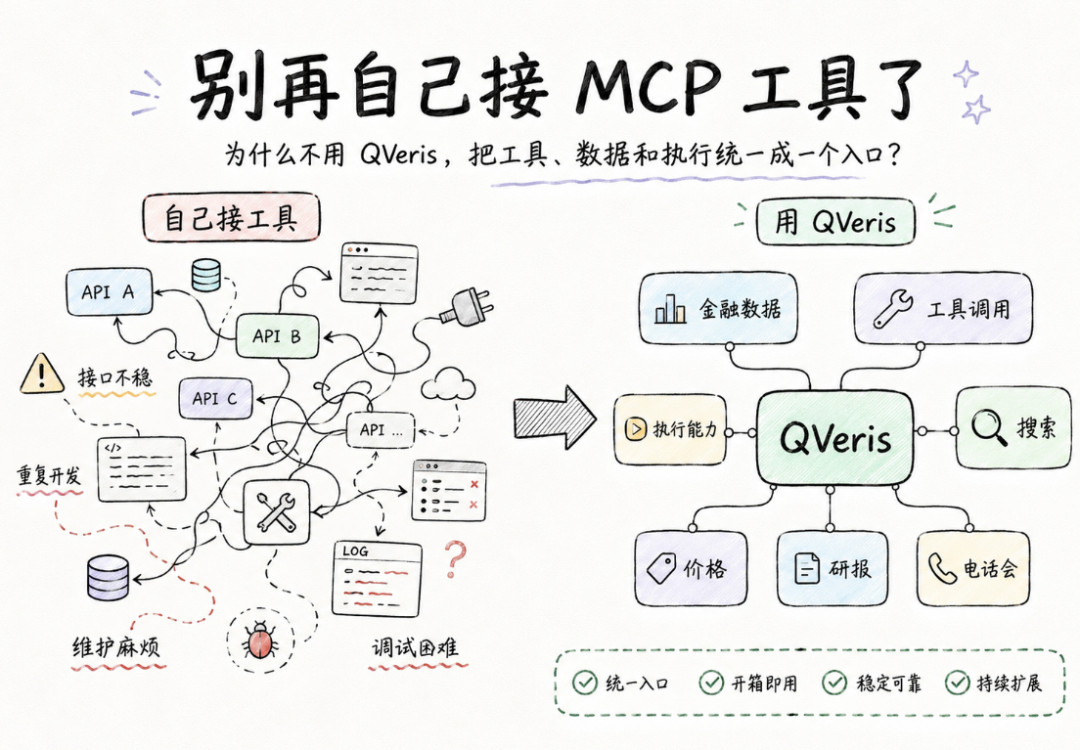
Stop Wiring Up MCP Tools Yourself. Use QVeris.

QVeris · Technical Deep Dive
Connecting a tool to a model is no longer the hardest part. The real challenge is getting an Agent, in a real environment, to reliably find the right tool, understand it, and use the parameters correctly.
Background
Over the past two years, expectations for Agents have risen quickly. Give one an API document, or connect an MCP service, and in many cases you can get the first call running in half an hour.
But “getting the first call to run” and “making it useful over the long term” are two very different things.
Tool calling is about whether the model decides to call a tool, whether it selects the right tool, and whether it fills in the parameters correctly.
MCP is about connecting tools to models through a unified interface.
So MCP matters, but the main problem it solves is “how to connect the tool.”
It does not automatically solve the following problems for you:
-
Which tools on the internet are actually worth discovering.
-
Who owns those tools, and where their documentation is scattered.
-
Which information represents real capabilities, and which information is just noise.
-
When a user sends a natural-language request, which tool should be selected.
-
How parameters should be completed, corrected, and normalized.
So the hard part today is no longer “can we connect it,” but “after it is connected, can we actually use it well.”
What Does It Really Take for an Agent to Use Tools Well?
At the core, I think there are four layers.
1. It First Needs to Discover Tools
Tool information on the internet is rarely organized neatly in one place. The official website explains the product, the developer docs describe the API, authentication lives on an auth page, and pricing plans and free quotas live on the pricing page. OpenAPI specs and MCP documentation often have yet another entry point.
So the first step is not invocation. The first step is finding the entry points and clarifying ownership.
2. It Also Needs to Turn Documentation Into Machine-Readable Data
Raw documentation is written for people, not for Agents to execute directly.
What actually enters the invocation path is not an entire documentation page, but a few essential facts: whose tool this is, what it can do, how to call it, and what limitations it has.
The hardest part of this step is not “can we extract it,” but three things:
-
It needs to be accurate, so descriptive text is not mistaken for executable capability.
-
It needs to be stable, so the same class of documentation does not produce one structure today and another tomorrow.
-
It needs to be efficient, so content that can be extracted by rules is not repeatedly re-read by a model every time.
Content such as OpenAPI is relatively well suited to rule-based parsing. Pricing-plan descriptions and hidden fields often still require semantic understanding.
If this step is wrong, retrieval and invocation downstream will be wrong with it. If it relies too heavily on LLMs, cost rises as well.
3. Once There Are Many Tools, Retrieval and Ranking Become the Core Problem
When there are only a few tools, invocation is usually manageable. Once the number of tools grows, the hardest problem is no longer “can we call it,” but “which one should we choose first.”
A similar name does not necessarily mean the best fit. The official tool is not necessarily the most stable. The newest tool is not necessarily the cheapest. Useful tool retrieval needs to consider fit, success rate, cost, and latency at the same time.
4. Finally, It Needs to Turn User Language Into Correct Parameters
This layer is more like translating human language into parameters.
The user’s input is usually not a standard API parameter. It may be natural language, an alias, colloquial wording, a typo, or even missing fields.
For example, when a user says “adults,” what the tool actually needs may be age > 18.
The user speaks in human terms. The tool expects conditions.
Without this layer, the model may look like it is calling tools, but in practice it is often just guessing parameters.
Several Real Engineering Problems
This article only covers the first half of the problem: several very real and easily underestimated issues in discovery, filtering, crawling, and structured parsing.
1. Not Every Link Is Worth Crawling
An entry point does not mean “crawl every link you see.”
Usually, you first collect entry points, then filter links, and only then decide whether to crawl. The first batch of entry points may come from GitHub aggregators, API directories, or MCP registries. At the link-filtering step, the core questions are: Is this a high-value page? Can it be matched to an existing service provider? If it cannot be matched, should a new provider be created? Should low-value links be discarded immediately?
The point is not to “crawl as much as possible,” but to capture the truly valuable entry points as reliably as possible.
A single documentation page can contain thousands of links, and every link may explode into more links when opened. For stability, this also needs to be maintained on a schedule.
2. Pages Can Be Very Long, and the Key Content Is Not Always in the Most Obvious Place
Many API documentation pages are absurdly long, far beyond the context length that large models can comfortably process.
What makes this harder is that the truly important information is not necessarily at the beginning. It may appear near the front, or it may be buried in the second half. Authentication, limits, pricing plans, and parameter constraints are often scattered across different locations.
So the real challenge is not downloading the page, but finding the most important parts at the lowest practical cost.
Three things need to be controlled at the same time: accuracy, recall, and cost.
Accuracy determines whether the system will misunderstand the content later. Recall determines whether key information will be missed. Cost determines whether this process can be sustained over time.
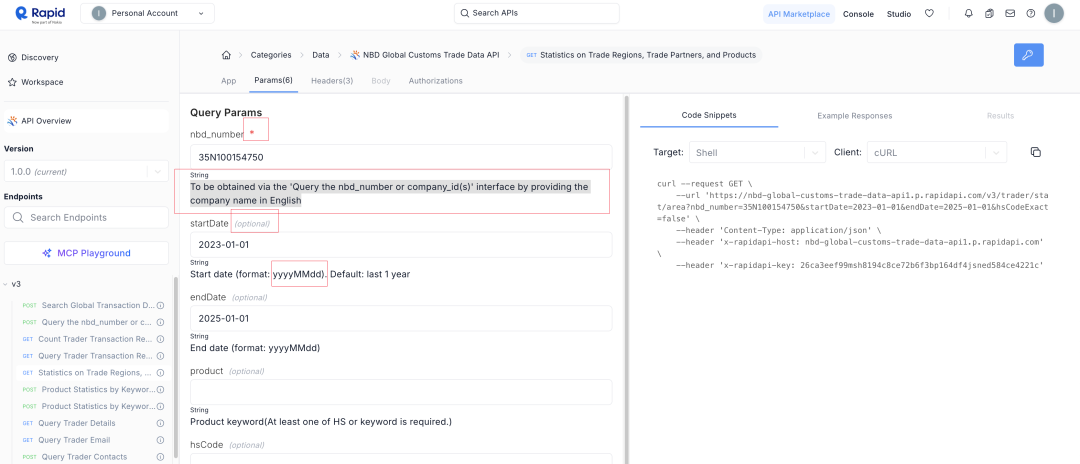
This time, we chose a docs page that looks very standardized: concise and clear, with required fields, descriptions, and formats. It looks like a large model should be able to produce the result immediately.
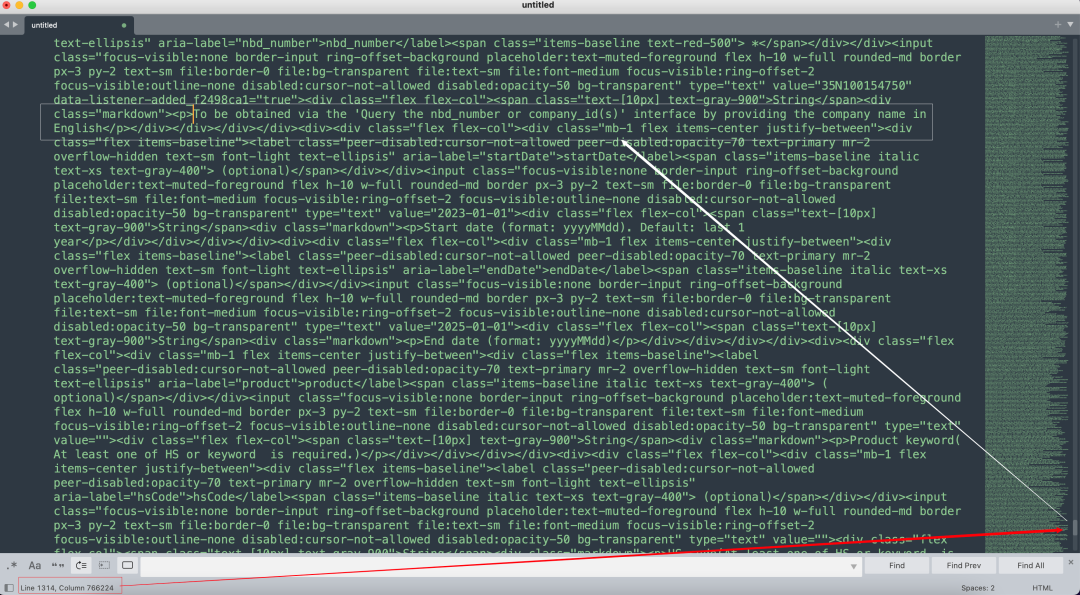
Buried at character 760,000 in a 990,000-character document.
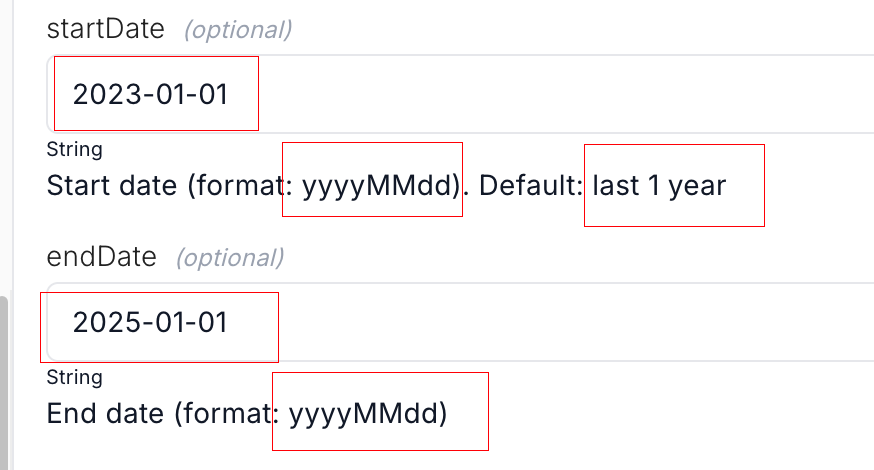
3. Structure Definitions Are Not an Add-On. They Directly Affect Invocation Quality.
Many people think of structure definitions as “the result of organizing documentation.” But if that structure is meant for an Agent, it is actually closer to part of the execution layer.
Whether field semantics are clear, parameter boundaries are accurate, and authentication information, pricing information, rate limits, enum values, and defaults are clearly specified will directly affect retrieval and correction downstream.
So a schema is not about “making things look more organized.” It is about helping the Agent make fewer mistakes.
This Article Covers the First Half
What we have covered here is mostly the supply side: how to find capabilities, how to decide whether they are worth crawling, and how to structure raw documentation reliably.
But for an Agent to truly use tools well, the second half is still missing: how to retrieve, how to rank, how to understand user input, and how to correct and normalize parameters.
So What Is QVeris Solving?
At a surface level, it is easy to understand this as “connecting another MCP server” or “collecting a bit more API documentation.”
But when you follow the chain further down, the real problem is not whether the tool is connected. The real question is whether there is a systematic capability that allows Agents to work reliably in an ever-growing world of tools.
That is the layer QVeris is designed to solve. It is not simply about connecting tools. It is about first doing discovery, organization, and structuring well, then building retrieval, correction, and invocation on top of a more stable foundation.
MCP solves “how to connect tools.”
QVeris aims to solve “after tools are connected, how can Agents actually use them in production?”
This article stops at the supply side. In the next article, if we continue the series, I will cover the second half in more detail: why retrieval becomes the core problem once there are enough tools; how ranking can be more than “the name looks most similar”; and why correction, completion, and normalization of user input directly determine invocation success rate.