
What to Watch For When Designing a Parameter Repair Pipeline
QVeris · Technical Practice
Background
We previously ran a round of tool-call failure analysis focused on a foundational question: after an Agent fails to call a tool, can it identify the cause from the failure logs and produce more reasonable parameter repair suggestions?
This is valuable because, in real-world tool calls, failures are not always caused by a broken tool or by user error. Often, the user's intent is correct and the tool is available, but the parameters generated by the model do not fully align with the provider's requirements.
For example, in a stock quote tool, the user may want to query quotes for a group of stocks. The intent is clear. But the tool may require multiple stock codes to be passed as an English-comma-separated string rather than a list.
Stock codes may need .SH / .SZ / .BJ suffixes. Indicator fields may only accept predefined enum values from the tool, rather than arbitrary Chinese indicator names.
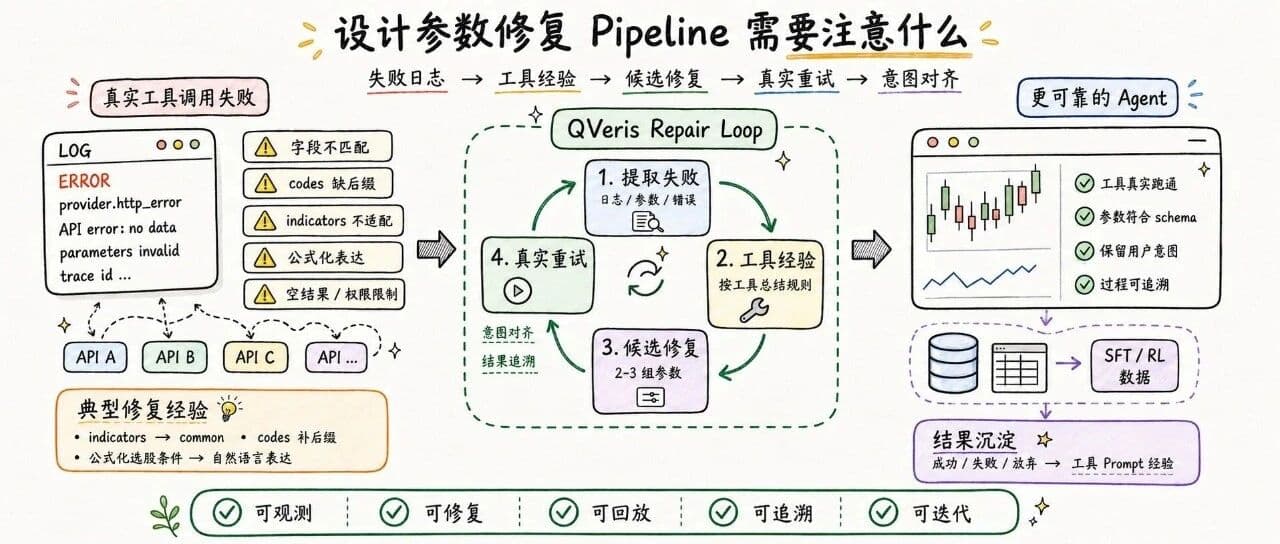
Around this problem, we designed a parameter repair pipeline. It organizes failure records for different tools, summarizes tool-specific experience, and tries to satisfy two goals at the same time when repairing parameters: first, make the parameters conform to the tool's truly executable schema; second, preserve the user's original intent as much as possible.
In other words, this pipeline does more than ask the model to explain "why it failed." It further connects tool experience summarization, parameter repair, and intent alignment into a verifiable process.
A Model Can Explain Errors, but Explanation Does Not Equal Successful Repair
Asking the model to analyze the cause of failure and output a suggested set of parameters may sound good enough. But in real tool calls, it is not.
Some suggestions look reasonable but still fail in actual execution. For example, in a real-time quote tool, the model may suggest changing indicators to basic. The word looks like a more basic and safer indicator set, but the real call may still return API error: no data. This shows that the issue lies beyond indicators.
Some suggestions can execute successfully but have already drifted away from the user's original intent. For example, if the user originally wanted to query overseas indexes and the model replaces them with A-share indexes, the tool may return data successfully, but that should not count as a high-quality repair.
Other suggestions delete the user's original conditions. For example, if the user provides a complex stock-screening strategy, the model may greatly shorten the conditions to increase the success rate. This may hit results, but it may also have lost the filtering logic the user truly cared about.
This shows that Agent Reliability cannot rely only on confident model explanations. It also needs real tool-call results for validation.
What We Built
This time, we organized the tool-call repair process into a pipeline.
The rough flow is:
-
Read real failed tool-call records.
-
Extract context such as tool ID, original parameters, error messages, status codes, and parameter help.
-
Call an LLM to analyze the cause of failure.
-
Generate up to 3 candidate repaired parameter sets for each failed record.
-
Execute every candidate parameter set through the real tool execution interface.
-
Record each candidate's success or failure, reason code, latency, cost, and returned result.
-
Based on the real recall results, summarize which rules are worth writing back into the tool prompt.
Why Generate Multiple Candidates
The risk of a single candidate is too high. When the model gives only one answer, it is hard to tell whether it is a faithful repair, a light rewrite, or a fallback substitution.
So now, for each failed case, we try to generate three types of candidates:
- The first type is the most faithful repair. It only changes clear errors such as field names, types, formats, suffixes, and enum values, while preserving the user's original intent as much as possible.
- The second type is a light rewrite. It preserves the main intent but rewrites the expression into a form the tool can understand more easily.
- The third type is a fallback relaxation. It is used when the original intent is difficult to recover directly, but it must clearly state that the semantics have been relaxed and cannot be treated as a fully faithful repair.
With this approach, we get not just one "answer," but a comparable candidate set. Real tool recall tells us which candidate can actually run, which candidate looks reasonable but fails, and which candidate succeeds only after relaxing the semantics.
Real Case: Parameter Repair for a Quote Tool
Take a real-time quote tool as an example. We saw a very typical class of issues: the indicators field did not fit the tool.
Some original requests passed:
indicators=f2,f3,f8,f10,...
These fields look very much like Eastmoney's F-parameter table, but they do not apply to the current tool.
Other requests passed:
indicators=最新价,涨跌额,涨跌幅,...
These Chinese indicator names are easy for users to understand, but the tool itself does not support this kind of custom indicator list.
After model analysis, the more stable repair was to preserve the original codes and change indicators uniformly to common. Real recall also validated this.
Another typical issue was missing stock-code suffixes.
For example, the original input was:
codes=301531,603407,...,920012,002902,301696,920200
This format is easy for people to understand, but the tool needs explicit market suffixes. During repair, we cannot mechanically append .SH or .SZ to everything. We need to infer by code segment: 301/300/001 usually get .SZ, 603/688 get .SH, and 920xxx should prioritize .BJ.
After real retries, the candidate that completed the suffixes and changed indicators to common successfully returned quote data.
This kind of case shows that the key to repairing structured tools is strict alignment with the tool schema: field names, field types, enum values, and code suffixes all need to be handled carefully.
Real Case: Natural-Language Rewrite for a Stock-Screening Tool
Another natural-language stock-screening tool has a different kind of problem. Its failures are often not field-format issues, but expression issues.
For example, one original input was:
120分钟均线金叉MA5MA34
People familiar with technical analysis can understand this expression, but for the tool it is too short and too formula-like, making direct calls prone to failure or empty results.
We rewrote it as:
120分钟K线 MA5上穿MA34 均线金叉
and specified searchtype=stock. The real call succeeded.
This shows that for natural-language stock-screening tools, the condition does not necessarily need to be translated into a more complex formula. On the contrary, rewriting a formula-like expression into a Chinese description the tool can recognize more easily is often more effective.
There was also a more complex strategy: the user wanted to screen for stocks that had "hit limit-up or doubled volume in the past month, were in long-term consolidation or the early stage of an uptrend, used a long upper shadow to test a previous high, had expanding volume, and showed strong bottom support."
In testing, we did not continue piling these conditions into a long sentence. Instead, we preserved the most core pattern features and rewrote the query into a shorter one:
-
Limit-up pullback, long upper shadow, testing previous high, expanding volume
This version successfully returned explainable results. The matched conditions included: previously hit limit-up, long upper shadow, new high in the highest price, and volume growth compared with the previous period.
Results like this may not cover every detail in the original strategy. But compared with directly returning no results, it at least preserves the core pattern the user cared about most and provides candidate results that can be evaluated further. For users, this is usually more valuable than simply telling them "no results."
A Small-Scale Data Set
We ran a round of testing on the first 20 original failure records.
Because each record generated 2 to 3 candidate repaired parameter sets, we ultimately produced 51 real tool recall calls. Of these, 48 succeeded and 3 failed, giving a candidate-level success rate of 94.12%.
In terms of latency, most of the time was spent in the model analysis stage. The additional overhead from real tool recall itself was relatively manageable.
This result shows that adding real recall on top of the existing analysis process can help us determine whether a repair plan can actually run end to end.
More importantly, it helps us filter out two types of candidates that should not be directly distilled into rules: one type looks reasonable but fails in practice, such as some basic indicators; the other succeeds in execution but has already relaxed the semantics, such as replacing the original query target with easier-to-succeed example parameters.
Success Rate Is Not the Only Metric
The biggest takeaway from this experiment was not that a particular case succeeded, but that we saw more clearly the difference between "the call succeeded" and "the repair was correct."
A candidate parameter set returning results successfully does not necessarily mean it is a good repair. We also need to check:
-
Whether it preserved the user's original target
-
Whether it preserved the user's original screening conditions
-
Whether it merely switched to sample parameters
-
Whether it deleted key constraints
-
Whether it relaxed a precise topic into a broader category
Closing
A more reliable Agent needs the ability to keep repairing beyond the tool call itself: understand the failure trace, propose parameter adjustments, and then validate whether the plan works through real tool execution results.
What we are building is a closed loop that connects tool calls, failure feedback, parameter repair, real retries, and experience updates. When these processes can be recorded, summarized, and iterated on, the Agent's use of tools will gradually evolve from isolated individual calls into an engineering process that can accumulate experience.
**
**
**
**
**
**