
Why Financial Agents Are So Hard to Build: A Few Pitfalls We Recently Hit
QVeris · Product Philosophy
We have recently been building a financial Agent product, internally called QFB.
The short version: it is not truly built yet.
If “built” means that a user can open it and reliably complete analysis, data retrieval, backtesting, comparison, reporting, saving, sharing, and publishing, then we are still far from that point.
But the work over this period has not been wasted. On the contrary, it has made one thing much clearer to us:
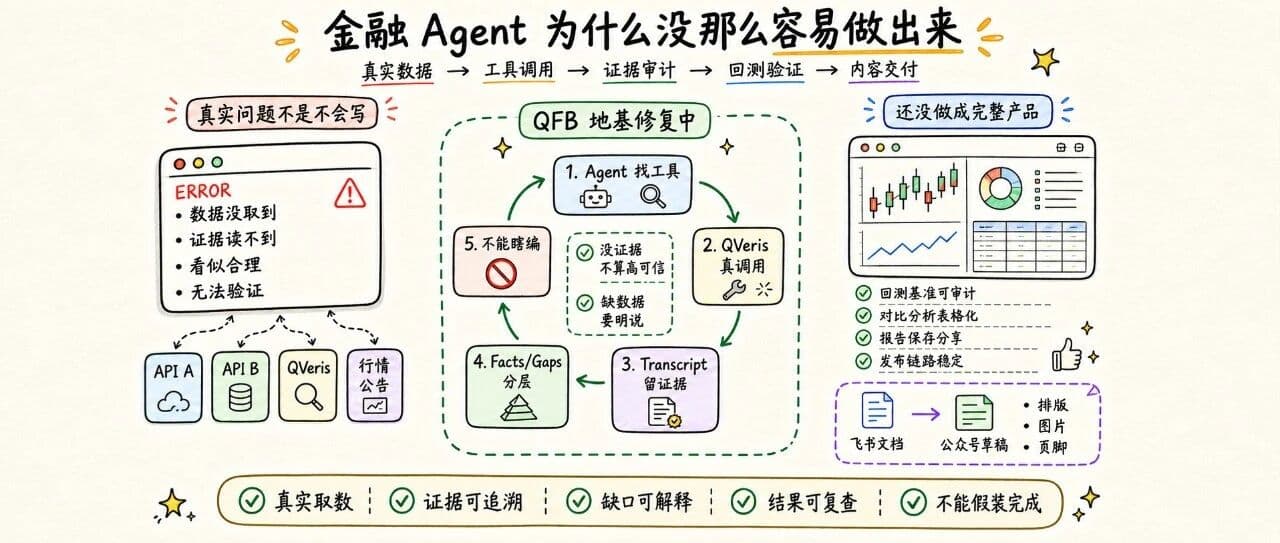
The hard part of a financial Agent is not getting a model to write an analysis. The hard part is making it operate under real data, real tools, and real user expectations without making things up, calculating carelessly, or overpromising.
This article is not a story about a product that has already succeeded.
It is about why this thing is harder to build than it looks, and what foundations we have been shoring up recently.
Users Do Not Want “AI That Sounds Smart”; They Want Data They Can Trust
We recently reviewed a QVeris subscription survey, with 66 valid responses. Several signals stood out clearly.
79% of users are individual investors.
They are already using many tools today: AKShare, East Money, iFinD, Tushare, Wind, TradingView, and some have built their own databases.
In other words, users do not lack tools.
The real problem is that these tools are fragmented. Their data interfaces, invocation methods, coverage, and stability all differ. What users want is not yet another query entry point, but a data capability layer that an Agent can call reliably.
In the survey, users were most concerned about:
-
Data not being accurate enough
-
Prices being too high
-
Data not being complete enough
-
Calls being unstable
-
Advantages over existing tools being unclear
There was another important signal: nearly 60% of users had already tried connecting QVeris to their own Agent.
This shows that the way financial data APIs are used is changing.
Previously, humans looked up data.
Now, in more and more scenarios, Agents find data, choose tools, call APIs, and then organize the results into analysis.
But this also introduces a new problem: once an Agent cannot get the data, it can easily start “guessing.”
In financial scenarios, that is dangerous.
QFB’s Biggest Problem Is Not the Interface; It Is That the Backend Cannot Cut Corners
One core tension has recently surfaced in QFB:
We want it to be as stable as a product, but behind it is still a set of Agent workflows under active refinement.
The easiest shortcut would be:
If the Agent fails to retrieve data, the backend directly calls QVeris once to fill the gap.
Or if the model does not receive complete results, it writes a seemingly reasonable analysis based on experience.
Both approaches can make a demo look better in the short term.
But over the long term, they directly undermine system trust.
So we later tightened the boundaries:
Real QVeris calls should happen inside the child agent workflow.
That means the Agent itself completes:
discover: finding potentially usable data tools.
inspect: understanding what parameters the tool needs and what structure it returns.
call: actually calling QVeris to retrieve results.
The backend should not secretly call QVeris directly from the runner or coordinator, and it should certainly not invent a result for the Agent when there is no evidence.
What the backend should really do is:
-
Orchestrate tasks
-
Read transcripts
-
Audit tool calls
-
Merge facts
-
Mark data gaps
-
Compute confidence
-
Generate a reviewable report structure
This sounds like engineering detail, but it actually determines the product’s baseline.
Because a financial Agent must be able to answer:
Is this conclusion supported by a real tool call?
If not, it cannot be packaged as high-confidence analysis.
At One Point, We Could Not Even Tell “Data Exists” from “Data Is Missing”
QFB had a very typical issue early on:
QVeris had clearly returned real data, but the system showed very low confidence, even with a long list of red gaps.
The user’s first impression was: this is unreliable.
But after digging deeper, we found that the problem was not necessarily “no data was retrieved.” It was that the backend validation layer failed to correctly recognize the data.
For example:
The transcript had not fully landed on disk before the backend started reading it.
The message format of the tool result did not match what the validation code expected.
A read failure was misclassified as the Agent not having called a tool.
As a result, the system cleared the facts and pushed confidence very low.
This kind of issue is extremely damaging.
It can misclassify real data as invalid data, and it can also cause users to underestimate the system’s capability.
What we later fixed was not “relaxing confidence,” but the validation logic itself:
We need to distinguish three things:
The Agent truly did not call a tool.
The Agent called a tool, but data was missing.
The validation layer failed to read the result, so it cannot confirm the state for now.
These three cases cannot be mixed together.
The third case, in particular, should not simply clear all facts. A more reasonable approach is to preserve low-confidence information and explicitly mark it as “unverified.”
This is also the difference between a financial Agent and an ordinary chatbot.
An ordinary chatbot can say, “I think.”
A financial Agent must explain, “What evidence do I have for thinking this?”
Backtesting Is Not Done Just Because You Produced a Return Curve
Backtesting is another pitfall.
Users do not only want a result like “the strategy returned 20%.”
They will continue asking:
What historical data period was used?
Do the asset data and benchmark data cover the same interval?
Is the frequency consistent?
Who is the benchmark?
If the benchmark cannot be retrieved, is the strategy result still meaningful?
When we recently added benchmark comparison to QFB backtesting, we also added hard constraints:
Benchmark data cannot be fetched by the backend directly calling QVeris.
A dedicated new subagent cannot be added.
Specific mappings such as AAPL versus SPY cannot be hardcoded.
The correct approach is: the backend only infers a default benchmark from the market segment and writes benchmarkSymbol into the task input; then it reuses the existing market_agent and lets it retrieve one additional set of benchmark candlesticks.
If retrieval fails, it writes a data_gap.
It cannot use the asset’s data as a fake benchmark.
It cannot invalidate the core backtest just because the benchmark is missing.
More importantly, the backtest result must explain “what data was used”:
-
Asset symbol
-
Benchmark symbol
-
Number of candlesticks
-
Date range
-
Frequency
-
Data source path
Otherwise, the user only sees a nice-looking curve, but cannot judge whether it is trustworthy.
This is also why QFB cannot claim to be finished yet.
For now, only part of the backtesting pipeline has become more auditable. It has not yet reached a complete product experience.
Comparative Analysis Cannot Just Be Scattered Across Natural Language
A request like “compare AAPL and MSFT” looks simple.
The model can easily write:
Apple has a higher share of hardware revenue, Microsoft has a stronger cloud business, and their valuation structures differ.
That paragraph may be correct, but it is not enough for a productized experience.
A real comparison report should be a side-by-side table across the same dimensions:
-
Current price
-
Price change
-
RSI / MACD
-
PE / PB
-
News sentiment
-
Key risks
Each cell should include evidence_refs where possible.
If a dimension is missing for a given asset, the cell should stay blank and the gap should be written into data_gaps.
The primary asset’s data cannot be used to fill the comparison asset.
News sentiment cannot substitute for valuation data.
The comparison cannot be considered complete just because the Agent “seems to have mentioned it” in free text.
So when we recently added a comparison section, the point was not merely to add another UI table. It was to turn comparative analysis from “prose” into a “structured report.”
This is not fully complete yet either.
But the direction is right: a financial Agent cannot only output a fluent paragraph. It has to structure the key dimensions so users can review them.
The WeChat Official Account Publishing Pipeline Became Usable Faster
Compared with QFB, the WeChat Official Account publishing pipeline is closer to a production tool that already runs.
Recently, the team has repeatedly worked on things like:
Converting Feishu documents into WeChat Official Account drafts.
Processing Feishu images, downloading them, and uploading them to the WeChat media library.
Automatically generating covers.
Automatically appending the QVeris AI footer and QR code.
Fixing first-line indentation in the WeChat editor.
Standardizing body font size to 16px.
Removing image borders.
Left-aligning titles, paragraphs, lists, and quotes.
This pipeline has a very clear goal: reliably turn a Feishu document into a WeChat Official Account draft.
Its problems are also more concrete: indentation, font size, images, cover, footer, draft box.
So it is easier to close the loop than QFB.
But it also reminds us of a practical reality:
If an Agent product is to enter a real workflow, it eventually has to deal with “delivery.”
It does not end when the model finishes answering.
Can the document be saved? Can the article be published? Can the result be reviewed? Can the format remain stable?
The WeChat Official Account pipeline solves content delivery.
QFB is still solving the trust foundation for financial analysis.
The two are not at the same level of difficulty.
Why I Do Not Want to Describe QFB as “Already Successful”
Because that would be misleading.
QFB has made some important progress:
-
The backend has started tightening QVeris call boundaries
-
Transcript / tool call validation is being hardened
-
Facts, gaps, and confidence are beginning to be layered
-
Backtesting has started adding benchmark comparison and data summaries
-
Comparative analysis is beginning to be structured
-
The Chat entry point is starting to avoid sending financial commands to a generic LLM
-
The WeChat Official Account publishing pipeline is gradually stabilizing
But all of that together does not mean “QFB has already been built.”
A more accurate description is:
The foundation of a financial Agent product is being filled in.
Many issues that can be glossed over in demos must be confronted directly here.
For example:
What happens when data cannot be retrieved?
What happens when a tool call fails?
What happens when the validation layer cannot read the transcript?
What happens when the LLM generates a polished statement with no evidence?
What happens when the user asks for a backtest benchmark, but benchmark data is missing?
What happens when the user wants to compare multiple assets, but each asset has incomplete data dimensions?
Before these questions are solved, we cannot say the product is finished.
We Now Believe More in a Slower Path
The fast path is: let the model write the answer directly.
The slower path is: let the Agent first find data sources, then call tools, then leave evidence behind, and then generate a report.
The even slower path is: make backtesting, comparisons, gaps, confidence, and publishing pipelines all reviewable structures.
But in financial scenarios, slower is worth it.
Users do not lack analysis that sounds intelligent.
What they lack is a system that can reliably connect to real data, acknowledge data gaps, preserve evidence, make the process reviewable, and deliver results.
QFB is not built yet.
But these recent pitfalls at least show this: if a financial Agent is truly going to be built, it cannot merely know how to chat.
It must learn how to gather evidence.